What’s the opposite of fragile?
Most people’s immediate answer is “robust” or “resilient”. But consider… if we subject something that is fragile to stress, shock, randomness or volatility, we can expect that it will be harmed. If we do the same to something that is robust or resilient, we can expect that it will resist harm – but won’t be any better off than when we started. But what if something that is subjected to stress, shock, randomness or volatility actually benefited? That would be the opposite of fragile: antifragile. This is the core theme of Nassim Nicholas Taleb’s book Antifragile: Things That Gain from Disorder.
What does fragility and antifragility look like?
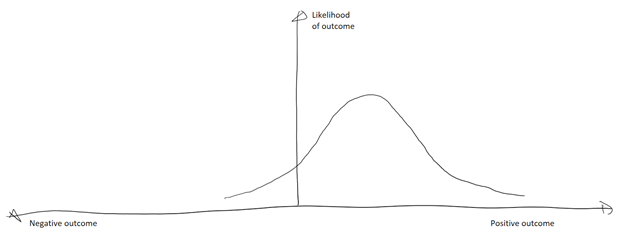
As human beings, we often think of things that have uncertainty or randomness as having a range of possible outcomes that are centered around some “most likely” outcome, as in the diagram below.
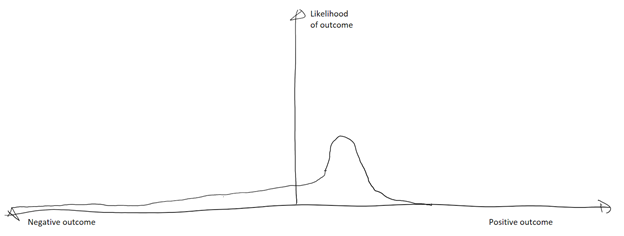
However in many domains, there is an asymmetry, where there are possible – but very unlikely – extreme outcomes, as illustrated in the diagram below (note that the likelihood of the extreme negative outcomes is much smaller than shown on my chart – but not zero). Such asymmetry is called a “long tail”. As a thought experiment, consider the case of reinsurance. Reinsurance is insurance purchased by an insurance company to cover their risk in the case of a catastrophic event. The reinsurer is paid premiums, and is only liable in the case of the catastrophic event. What’s the maximum upside for the reinsurer? If no claims are paid, they earn the value of the premiums paid (plus, whatever investment income they have managed to make from holding that money.) But what’s the maximum downside? A single, unpredictable extreme event can have enormous negative consequences. Taleb calls this a negative “Black Swan” event, and uses the example of asbestos claims almost destroying Lloyd’s of London. Since “Black Swan” events are unpredictable, calculating probability is of limited use, but we can detect these kinds of asymmetries and identify such situations as fragile. Taleb also points out that both uncertainty and time are as good as stress, shock, randomness and volatility as far as being triggers for asymmetric outcomes.
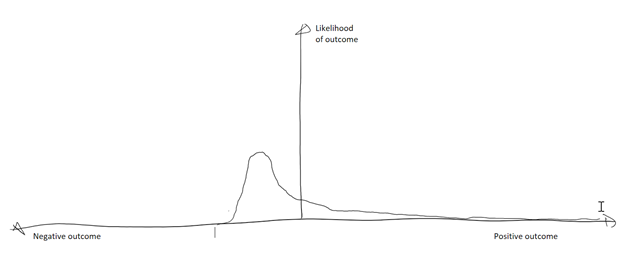
Positive Asymmetry – the Antifragile
If we look at the reverse of negative asymmetry, we find positive asymmetry, such as in the diagram below. Innovation can look like this: what’s the maximum downside? We lose the money invested. What’s the upside? Sometimes we’ll innovate something that makes money; usually we’ll learn something; rarely we’ll innovate something that makes a lot of money – a positive “Black Swan” event.
Taleb also points out that optionality and tinkering are both antifragile. Optionality is just that: having options. Taking an innovation perspective again (and also thinking about the pivot or persevere mentality of The Lean Startup), if we keep our eyes open we can detect when our innovation has revealed a better option and switch paths to that. Taleb uses the example of mobile phone company Nokia starting as a paper mill. Such options tend to have a ratchet effect, where what we have learned moves us forward, not backward. Tinkering is evolutionary experimentation: we try something, and if it has benefit, we keep it and build on it; if it does not have benefit, we drop it. The key is retaining our optionality and having the wisdom to recognize when something has a beneficial outcome.
What can we learn from this? How can we apply it?
First, detect fragility and minimize exposure. Taleb makes the point that it doesn’t matter how much upside you have from a situation, if the situation is inherently fragile then a single negative “Black Swan” event can wipe you out. His advice, therefore, is to first detect and reduce your exposure to fragility.
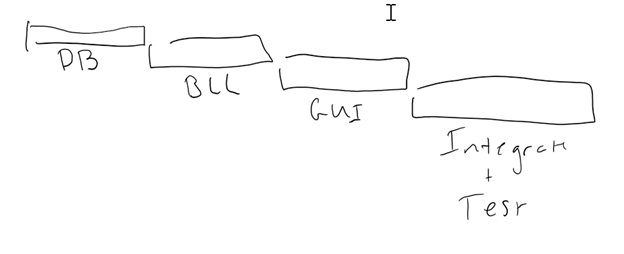
Traditional Software Schedules are Fragile
Consider the traditional software schedule below. Traditional software schedules typically divide work into layers (horizontal slices), and then into tasks (not shown in my level of detail here).
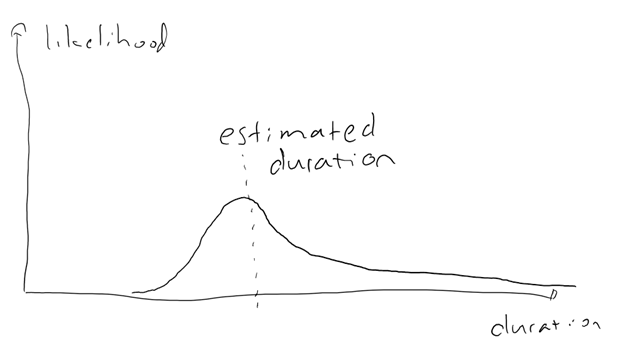
There are at least several fragilities in this approach. The first is the likelihood of completing any given task in the time estimated. Consider the chart below: If I estimated a task to take 3 days, and it goes really well, I might complete it in 2 days, but it is unlikely I will complete it in 1 hour. But there are any number of things (my development environment got corrupted, my hard disk went bad, I did not understand what was needed to make my task work, …) that could make the task take longer – or much longer. Here is a fragility due to asymmetry again. (The horizontal axis is reversed from the previous charts, because in this case a longer duration is a more negative outcome.) Also, consider that due to dependencies, these kinds of fragilities tend to stack (accumulate), rather than negate each other.
Another fragility to consider in the traditional software schedule is loss of optionality. It may not be until I am into the GUI or even the Integration phase of this project that I detect that the DB choices I have made won’t actually work well, but at that point I have invested heavily in the existing DB approach and may not have the time or budget to adjust. This makes my project fragile to my design decisions.
Integration and test are discovery activities where we find out (get feedback on) the work we have done so far. By leaving these until late in the project, we defer learning that may cause us to need to rework significant portions of what we have done.
Agile project planning, by comparison, focuses us on creating small, fully tested vertical slices, and keeping our optionality open sprint-to-sprint. In a small slice and the timebox of a sprint, the largest cost of going down the wrong path is the time spent on a sprint – or less: we often timebox risky activities and explorations to limit their cost. Vertical slices allow us to reveal early learning so that we can make course corrections. And by constantly adjusting the product backlog and release plans to current knowledge, we keep our options open with respect to finding new and better aspects of the product or the process.
Are our designs fragile or antifragile?
One way of using this lens is to look at our software designs and architectures. If we are locked into a single database vendor, for example, we might be fragile with respect to that vendor’s product and viability. In contrast, when we abstract our dependencies on 3rd party tools and libraries, we give ourselves more optionality and less fragility.
Design concepts such as Single Responsibility Principle (a class should do one thing and do it well) and Dependency Injection promote antifragility, because we can more easily rearrange our software to adapt to new needs. These are of course supported by test automation, so that we can more easily detect when we’ve broken something.
Another consideration is performance and scalability. A fragile system is one in which performance degrades exponentially as the load goes up. This means that the system is more vulnerable to unexpected events (e.g. a regional Internet outage could trigger an unexpected load and a cascade failure of the system).
Are our teams and organizations fragile or antifragile?
Teams and organizations that go for 100% efficiency tend to be fragile, because there is insufficient slack (both in time and in redundancy of knowledge/skill) to adapt to unexpected changes. Teams and organizations that deliberately learn from “things that didn’t go well” (e.g. software defects, failed business proposals, etc.) tend towards antifragile, because disorder and randomness are harnessed to promote growth.
What about our agile methods?
Tinkering, in the form of experiments with potentially better ways of doing things, is inherently antifragile, as these can be designed to have a positive “long tail”, so that the cost of experimentation is contained but the potential for better outcomes is not constrained. Along with optionality and the ratcheting effect of learning, these give us the possibility of continually improving our outcomes.
How will you apply these concepts?
I’ve really only “scratched the surface” in terms of potential applications of Taleb’s ideas. I can imagine many more ways of taking this work and using it for positive outcomes. What about you? Will you take these concepts and put them to work? And if so, how?
Originally published as a two-part series July 19th and 28th, 2016 on the Innovative Software Engineering blog. Republished with permission.